La suite collect introduite avec le version 17 va t-elle remplacer outreg2 et autres commandes de mise en forme et d’exportation de tableaux? Pas encore un tutoriel, dès éléments sont encore obscurs, mais avec quelques copier-coller issus des fichiers d’aide, on présentera deux exemples avec des régressions.
Principe de la suite collect:
Il s’agit d’un ensemble de commandes pour paramétrer le style des tableaux que l’on souhaite exporter dans des formats comme .doc, .xls, .tex, .html ou .md
Un style peut être enregistré et utilisé à plusieurs reprises.
Un style enregistré peut être modifié pour un tableau spécifique.
A partir de la base nanhes21:
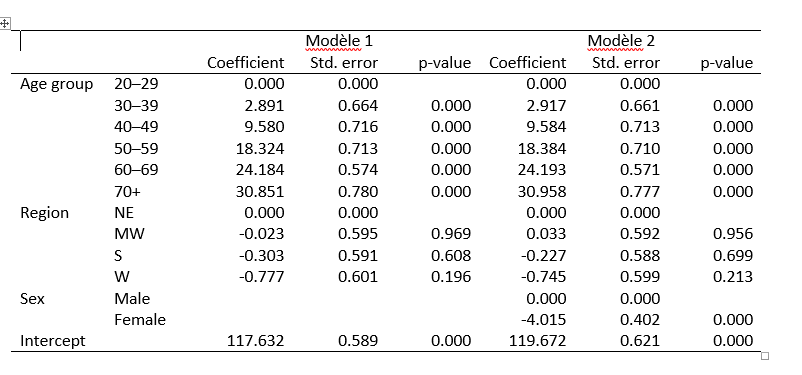
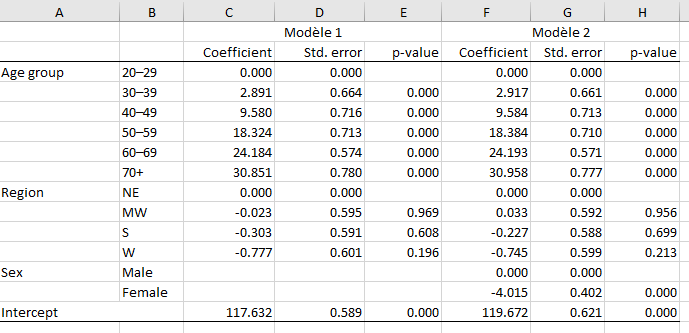
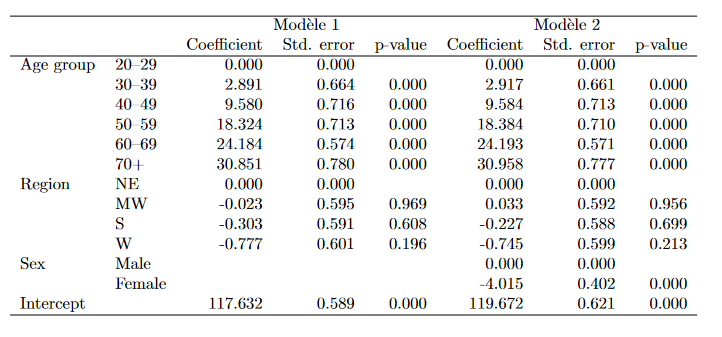
Exemple1: Deux modèles avec spécifications différentes. Il s’agit d’une simple OLS qui mesure la pression artérielle
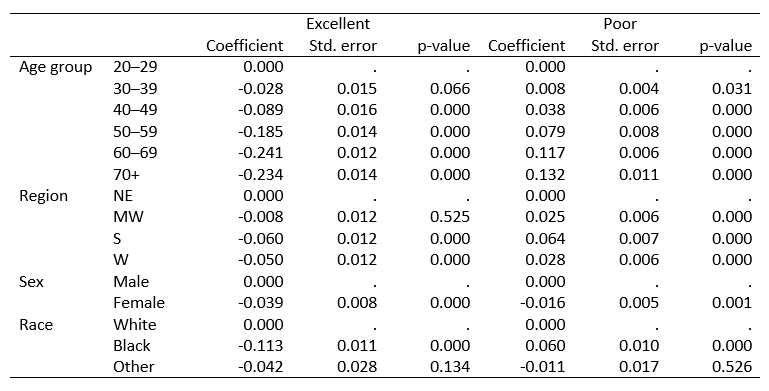
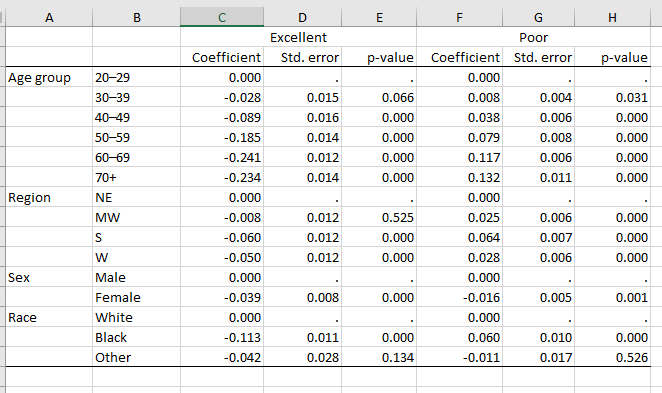
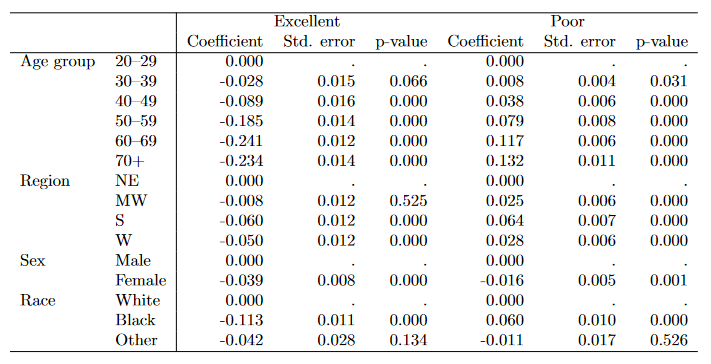
Exemple2: AME après un modèle multinomial avec les outcomes en colonne. Pour des raisons de place, je n’ai gardé que deux des quatres outcomes dans l’output. J’utilise une multinomiale même s’il s’agit d’une variable ordinale; j’ai seulement pris de que j’avais sous la main pour l’exemple.
Dans les tableaux les informations reportées sont les effets marginaux (_r_b), les erreurs type (_r_se) et les p-values (_r_p). D’autres sont disponibles commes les bornes des intervalles de confiances.
Définition d’un style pour une suite de tableaux
Rappel: un tuto plus complet viendra ultérieurement (s’il y a une demande)
collect style rowsplit, dups(first) // ajoute le label de la variable à gauche comme nom de variablecollect style column, dups(center) // permet de ne pas multiplier le nombre de cellule sur la première lignecollect style cell result[_r_b _r_se _r_p], nformat(%8.3f) // décimales des valeurs (ici idem)collect style cell border_block, border(right, pattern(nil)) // bête copier-coller, je n'ai pas testé avec/sanscollect layout (colname) (cmdset#result) // Cette ligne semble obligatoire même si on ne définit pas de stylecollect save multimod , replace// sauvegarde dans repertoire temporaire du style appelé ici multimod (format .stjson)
(dimension result not found)
(dimension border_block not found)
(dimension colname not found)
(dimension cmdset not found)
Collection: default
Rows: colname
Columns: cmdset#result
Your layout specification does not identify any items.
(collection default saved to file multimod.stjson)
On peut également ajouter un titre, modifier les labels des variables, je pense aussi les libellées des colonnes pour les indicateurs (par exemple AME au lieu de Coefficient).
le fichier tex1.tex généré avec collect export donne le tableau brut balisé. Le fichier peut être inséré dans un document Latex avec \estauto{nom_fichier.tex} ou \input{nom_fichier.tex}
Juste une petite remarque sur les notes de bas de tableau. collect gère également leur présence et leur mise en forme, mais le code généré semble systématiquement les aligner au centre. A creuser, sinon il faut modifier le code Latex pour les aligner à gauche. Par exemple:
Pour la sortie, j’ai fait également quelques modifs au niveau du texte et changé les valeurs des baselines de 0.00 à Ref
Margins avec mlogit
Le programme est très simple, et au final on arrive à produire rapidement un output très satisfaisant avec les résulats des différentes modalités en colonne.
Je n’ai pas reproduit la fin du programme avec collect export.
Rappel: j’ai seulement reporté les AME pour seulement deux catégories excellent et poor
Il est bien évidemment possible de programmer et d’utiliser les styles à la volée. A minima, il semblerait que pour les résultats de régression la ligne collect layout (colname) (cmdset#result) soit obligatoire.
Pour un simple modèle (exemple1 Ols), sans style.
collect clearquietly: collect _r_b _r_se _r_p: regress bpsystol i.agegrp i.region i.sexcollect preview* Your layout specification does not identify any items.collect clearcollect layout (colname) (cmdset#result)quietly: collect _r_b _r_se _r_p: regress bpsystol i.agegrp i.region i.sexcollect preview
Your layout specification does not identify any items.
(dimension colname not found)
(dimension cmdset not found)
(dimension result not found)
Collection: default
Rows: colname
Columns: cmdset#result
Your layout specification does not identify any items.
------------------------------------------
| 1 1 1
| Coefficient Std. error p-value
----------+-------------------------------
20–29 | 0 0
30–39 | 2.917042 .6613269 0.000
40–49 | 9.584328 .7129385 0.000
50–59 | 18.38351 .7100856 0.000
60–69 | 24.1932 .5711481 0.000
70+ | 30.95843 .7768639 0.000
NE | 0 0
MW | .0329983 .5917749 0.956
S | -.2269237 .5877579 0.699
W | -.7447052 .5985115 0.213
Male | 0 0
Female | -4.01548 .4021621 0.000
Intercept | 119.6719 .6205858 0.000
------------------------------------------
Au lieu de sélectionner des items comme _r_b _r_se _r_se, on peut directement tous ceux qui sont disponibles avec collect get. Pas forcément conseillé avec les exemples car chaque regression enregistre 10 information (bornes des IC, degré de liberté, statistique t pour l’Ols, sa valeur absolue…)
Pour info la ligne avec collect get est: collect get: regress bpsystol i.agegrp i.region i.sex
Le builder
Stata a installé un builder intéractif pour mettre en forme. Je ne suis pas du tout à l’aise avec ce genre d’outil, pour ne pas dire complètement nul.