| Packages | Fonctions |
|---|---|
| readstata13 | read.dta13 |
| rio | factorize |
| dyplyr |
mutate group by summerize
|
| questionr | freq |
| Base R | str - summary |
Les enquêtes Démographiques et de Santé (DHS) sont régulièrement utilisées par les chercheurs travaillant sur le continent africain, l’amérique centrale et du sud ou l’asie du sud.
Les fichiers issus de questionnaires Ménages, Femmes et Hommes ont la même structure dans tous les pays participant à chaque phase de l’enquête : 400 enquêtes dans 90 pays en 2023. Les régles de recodage sont définies dans le Standard recode manuel DHS 6
Cet exemple s’inspire des fiches pédagogiques produites dans le cadre de l’école d’été du Collège International des Sciences Territoriales avec la lecture de fichiers téléchargés, l’identification des types de variables et la production d’indicateurs et de graphiques simples.
Documentation :
Installation des packages :
install.packages("readstata13")
install.packages("rio")
install.packages("dyplyr")
install.packages("questionr")Fichiers à disposition :
Les fichiers contiennent 10% des individus des tables téléchargées du site enquêtes DHS au format Stata (.dta) et rassemblent les réponses de l’enquête passée au Bénin en 2017 (vague 7).
Nous utilisons ici uniquement les fichiers niveau Ménages, niveau Femmes, et niveau Enfants de l’enquête passée au Bénin en 2017 (vague 7). Ces fichiers sont initialement au format Stata (.dta).
| Pays | Niveau Ménages | Niveau Femmes | Niveau Enfants |
|---|---|---|---|
| Bénin | B1_BN | B2_BN | B4_BN |
On va selectionner quelques variables à partir des fichiers initiaux.
Appel des packages
Création de tables R à partir de fichiers Stata
- Table BE_Menages
On lit le fichier contenant les caractéristiques des logements des Ménages et on sélectionne les variables suivantes :
| Variable | Label / Intitulé |
|---|---|
| hhid | Case Identification |
| hv000 | Country code and phase |
| hv001 | Cluster number |
| hv002 | Household number |
| hv003 | Respondent’s line number |
| hv024 | Region |
| hv025 | Type of place of residence |
| hv219 | Sex of head of household |
| hv220 | Age of head of household |
| hv219 | Has telephone (land-line) |
| hv227 | Has mosquito bed net for sleeping |
| hv230b | Presence of water at hand washing place |
Be_Menages = read.dta13("datas/B1_BN.dta",generate.factors=T,fromEncoding="latin1") %>%
factorize() %>%
data.frame() %>%
# Selection des variables
select(c(hhid,hv000,hv001,hv002,hv003,hv024,hv025,hv230b,hv227,hv219,hv220,hv221)) Afficher le contenu de la table
str(Be_Menages)'data.frame': 1416 obs. of 12 variables:
$ hhid : chr " 1 46" " 1 119" " 1 131" " 1 143" ...
$ hv000 : chr "BJ7" "BJ7" "BJ7" "BJ7" ...
$ hv001 : int 1 1 1 1 2 3 3 4 6 6 ...
$ hv002 : int 46 119 131 143 25 11 47 149 37 63 ...
$ hv003 : Factor w/ 10 levels "incomplete household",..: 5 2 5 2 2 2 5 5 5 2 ...
$ hv024 : Factor w/ 12 levels "alibori","atacora",..: 1 1 1 1 1 1 1 1 1 1 ...
$ hv025 : Factor w/ 2 levels "urban","rural": 2 2 2 2 2 2 2 2 2 2 ...
$ hv230b: Factor w/ 2 levels "water not available",..: NA NA NA NA 1 NA NA 1 NA 1 ...
$ hv227 : Factor w/ 2 levels "no","yes": 2 2 1 1 2 1 2 2 2 2 ...
$ hv219 : Factor w/ 2 levels "male","female": 1 1 1 1 1 2 1 1 1 1 ...
$ hv220 : Factor w/ 78 levels "16","17","18",..: 50 20 22 58 32 50 13 25 21 29 ...
$ hv221 : Factor w/ 2 levels "no","yes": 1 1 1 1 1 1 1 1 1 1 ...- Table BE_Femmes
On lit le fichier contenant les caractéristiques des Femmes enquêtées et on sélectionne les variables :
| Variable | Label / Intitulé |
|---|---|
| caseid | Case Identification |
| v000 | Country code and phase |
| v001 | Cluster number |
| v002 | Household number |
| v003 | Respondent’s line number |
| v704 | Husband/partner’s occupation |
| v705 | Husband/partner’s occupation (grouped) |
| v716 | Respondent’s occupation |
| v149 | Educational attainment |
Be_Femmes = read.dta13("datas/B2_BN.dta",generate.factors=T,fromEncoding="latin1") %>%
factorize() %>%
data.frame() %>%
# Selection des variables
select(c(caseid,v000,v001,v002,v003,v704,v705,v716,v149))Afficher le contenu de la table
str(Be_Femmes)'data.frame': 1593 obs. of 9 variables:
$ caseid: chr " 1 15 4" " 1 46 2" " 1 46 5" " 1 52 5" ...
$ v000 : chr "BJ7" "BJ7" "BJ7" "BJ7" ...
$ v001 : int 1 1 1 1 1 1 2 2 3 3 ...
$ v002 : int 15 46 46 52 76 119 13 76 2 13 ...
$ v003 : int 4 2 5 5 2 3 2 9 27 2 ...
$ v704 : Factor w/ 238 levels "not working and didn't work in last 12 months",..: 130 23 126 22 7 5 237 22 1 150 ...
$ v705 : Factor w/ 12 levels "did not work",..: 4 6 4 6 5 5 11 6 1 4 ...
$ v716 : Factor w/ 238 levels "not working and didn't work in last 12 months",..: 232 159 153 1 156 1 156 1 64 156 ...
$ v149 : Factor w/ 6 levels "no education",..: 2 1 1 1 1 1 1 1 1 4 ...- Table BE_Enfants
On lit le fichier contenant les caractéristiques des Enfants (avec Education et santé) et on sélectionne les variables :
| Variable | Label / Intitulé |
|---|---|
| caseid | Case Identification |
| v001 | Cluster number |
| v002 | Household number |
| v003 | Respondent’s line number |
| v716 | Respondent’s occupation |
| v717 | Respondent’s occupation (grouped) |
| v719 | Respondent works for family, others, self |
| v218 | Number of living children |
| v130 | Religion |
| v131 | Ethnicity |
| v101 | Region |
| v102 | Type of place of residence |
| v106 | Highest educational level |
| v107 | Highest year of education |
| v113 | Source of drinking water |
| v115 | Time to get to water source |
Be_Enfants = read.dta13("datas/B4_BN.dta",generate.factors=T,fromEncoding="latin1") %>%
factorize() %>%
data.frame() %>%
# Selection des variables
select(c(caseid,v000,v001,v002,v003,v716,v717,v719,v218,v130,v131,v101,v102,v106,v107,v113,v115))Afficher le contenu de la table
str(Be_Enfants)'data.frame': 1359 obs. of 17 variables:
$ caseid: int 225 482 532 563 642 1212 1648 2258 3135 3178 ...
$ v000 : chr "BJ7" "BJ7" "BJ7" "BJ7" ...
$ v001 : int 2 4 5 5 6 1 1 2 3 3 ...
$ v002 : int 2 8 3 6 4 21 64 25 13 17 ...
$ v003 : int 5 2 2 3 2 2 8 8 5 8 ...
$ v716 : Factor w/ 238 levels "not working and didn't work in last 12 months",..: 23 4 62 156 156 153 1 1 62 153 ...
$ v717 : Factor w/ 12 levels "not working",..: 6 5 9 4 4 4 1 1 9 4 ...
$ v719 : Factor w/ 3 levels "for family member",..: 1 3 3 3 3 3 NA NA 3 3 ...
$ v218 : int 1 2 4 4 5 4 5 1 3 5 ...
$ v130 : Factor w/ 11 levels "vodoun","other traditional",..: 3 4 3 10 3 3 3 3 3 3 ...
$ v131 : Factor w/ 10 levels "adja and related",..: 2 2 2 2 7 2 7 7 2 2 ...
$ v101 : Factor w/ 12 levels "alibori","atacora",..: 1 1 1 1 1 1 1 1 1 1 ...
$ v102 : Factor w/ 2 levels "urban","rural": 2 2 2 2 2 2 2 2 2 2 ...
$ v106 : Factor w/ 4 levels "no education",..: 1 1 1 1 1 1 1 1 1 1 ...
$ v107 : Factor w/ 8 levels "no years completed at level v106",..: NA NA NA NA NA NA NA NA NA NA ...
$ v113 : Factor w/ 21 levels "piped water",..: 10 10 9 14 10 10 10 21 10 10 ...
$ v115 : Factor w/ 33 levels "0","1","10","100",..: 3 3 31 3 18 14 31 32 31 14 ...La variable caseid de la table Enfants du Bénin est de type entier (int) alors que la variable caseid d’autres tables Enfants (par exemple du Togo ou du Mali) est chaîne de caractères (char). On va changer son type en chaîne de caractères avec la fonction mutate à laquelle sera associée une autre fonction: as.character.
Be_Enfants= Be_Enfants %>%
mutate(caseid=as.character(caseid)) Comprendre l’organisation des tables entre elles
On s’attache en particulier aux identifiants des individus de chacune des tables Menages, Femmes et Enfants pour en comprendre l’organisation et les liens possibles entre elles.
- Table ménage
| Variable | Label / Intitulé |
|---|---|
| hhid | Case Identification |
| hv001 | Cluster number |
| hv002 | Household number |
| hv003 | Respondent’s line number (answering Household questionnaire) |
| … | … |
- Table Femmes et table Enfants
| Variable | Label / Intitulé |
|---|---|
| caseid | Case Identification |
| v001 | Cluster number |
| v002 | Household number |
| v003 | Respondent’s line number |
| … | … |
On pourra reconstituer le numéro du ménage à laquelle appartient chaque femme de la table Femmes à l’aide des variables v001, v002 et v003 qui sont des chaînes de caractères (char) que l’on pourra concaténer avec la fonction paste (casesid=v001+v002+v003).
Pour illuster ce propos, nous pouvons regarder l’organisation de fichiers issus de 5 ménages enquêtés au Togo en 2013.
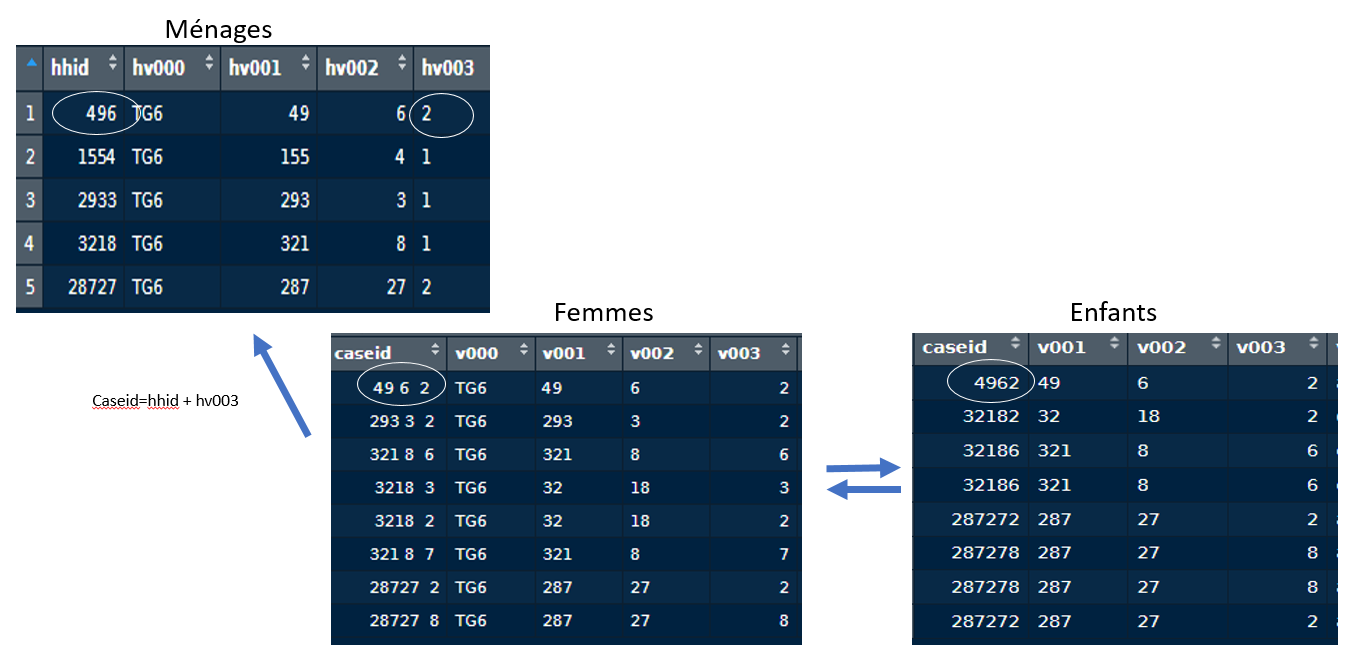
Caseid, l’identifiant du premier enfant de la table Enfants, a pour valeur 4962. Il appartient au 1er ménage de la table Ménages.
Les 5e et 6e enfants de la table Enfants appartiennent au 5e ménage de la table Ménages et on retrouve la correspondance avec la table Femmes.
On pourra donc faire des jointures entre les tables Ménages, Femmes et Enfants.
Statistiques univariées
Afficher le contenu des tables
Pour rappel, la fonction str(matable) permet d’afficher le nombre d’observations et de variables d’une table R mais aussi son type qui conditionne l’utilisation de fonctions.
Une variable qualitative peut être stockée en factor ou character et une variable numérique en integer pour des nombres entiers).
str(Be_Menages)'data.frame': 1416 obs. of 12 variables:
$ hhid : chr " 1 46" " 1 119" " 1 131" " 1 143" ...
$ hv000 : chr "BJ7" "BJ7" "BJ7" "BJ7" ...
$ hv001 : int 1 1 1 1 2 3 3 4 6 6 ...
$ hv002 : int 46 119 131 143 25 11 47 149 37 63 ...
$ hv003 : Factor w/ 10 levels "incomplete household",..: 5 2 5 2 2 2 5 5 5 2 ...
$ hv024 : Factor w/ 12 levels "alibori","atacora",..: 1 1 1 1 1 1 1 1 1 1 ...
$ hv025 : Factor w/ 2 levels "urban","rural": 2 2 2 2 2 2 2 2 2 2 ...
$ hv230b: Factor w/ 2 levels "water not available",..: NA NA NA NA 1 NA NA 1 NA 1 ...
$ hv227 : Factor w/ 2 levels "no","yes": 2 2 1 1 2 1 2 2 2 2 ...
$ hv219 : Factor w/ 2 levels "male","female": 1 1 1 1 1 2 1 1 1 1 ...
$ hv220 : Factor w/ 78 levels "16","17","18",..: 50 20 22 58 32 50 13 25 21 29 ...
$ hv221 : Factor w/ 2 levels "no","yes": 1 1 1 1 1 1 1 1 1 1 ...La table contient 1416 observations et 12 variables. On dénombre 1416 ménages au Bénin.
La variable hhid (identifiant du ménage) est de type character (char), la variable hv001 (cluster number) est de type entier (int) et la variable hv003 (numéro du répondant) est de type facteur (Factor).
Répartition des ménages …
- Selon le type de commune
La variable hv025 (milieu rural ou urbain) est une variable qualitative de type facteur (Factor) .
# Comme la variable est de type Factor on peut utiliser la fonction summary qui va afficher les effectif
summary(Be_Menages$hv025)urban rural
616 800 # On utilise la fonction freq du package questionr pour afficher aussi les %
freq(Be_Menages$hv025, cum=F) n % val%
urban 616 43.5 43.5
rural 800 56.5 56.5On trouve 800 Menages habitant en milieu rural, soit près de 57% des ménages interrogés au Bénin dans notre échantillon.
- …Selon le fait de posséder une moustiquaire
On prend la variable hv227:Has mosquito bed net for sleeping de la table Ménages pour calculer la répartition et faire le graphique associé
Répartition
freq(Be_Menages$hv227, cum=F) n % val%
no 89 6.3 6.3
yes 1327 93.7 93.7Graphique
ggplot(Be_Menages) +
aes(x = hv227) +
geom_bar(position = "dodge", fill = "#112446") +
coord_flip() +
theme_minimal()
Près de 94% des ménages de notre fichier possèdent une moustiquaire pour dormir.
- …Selon l’accès à l’eau pour se laver les mains
On prend la variable hv230b (Presence of water at hand washing place) de la table Ménages
Répartition
# Répartition
freq(Be_Menages$hv230b, cum=F) n % val%
water not available 441 31.1 57
water is available 333 23.5 43
NA 642 45.3 NAGraphique
ggplot(Be_Menages) +
aes(x = hv230b) +
geom_bar(position = "dodge", fill = "#112446") +
coord_flip() +
theme_minimal()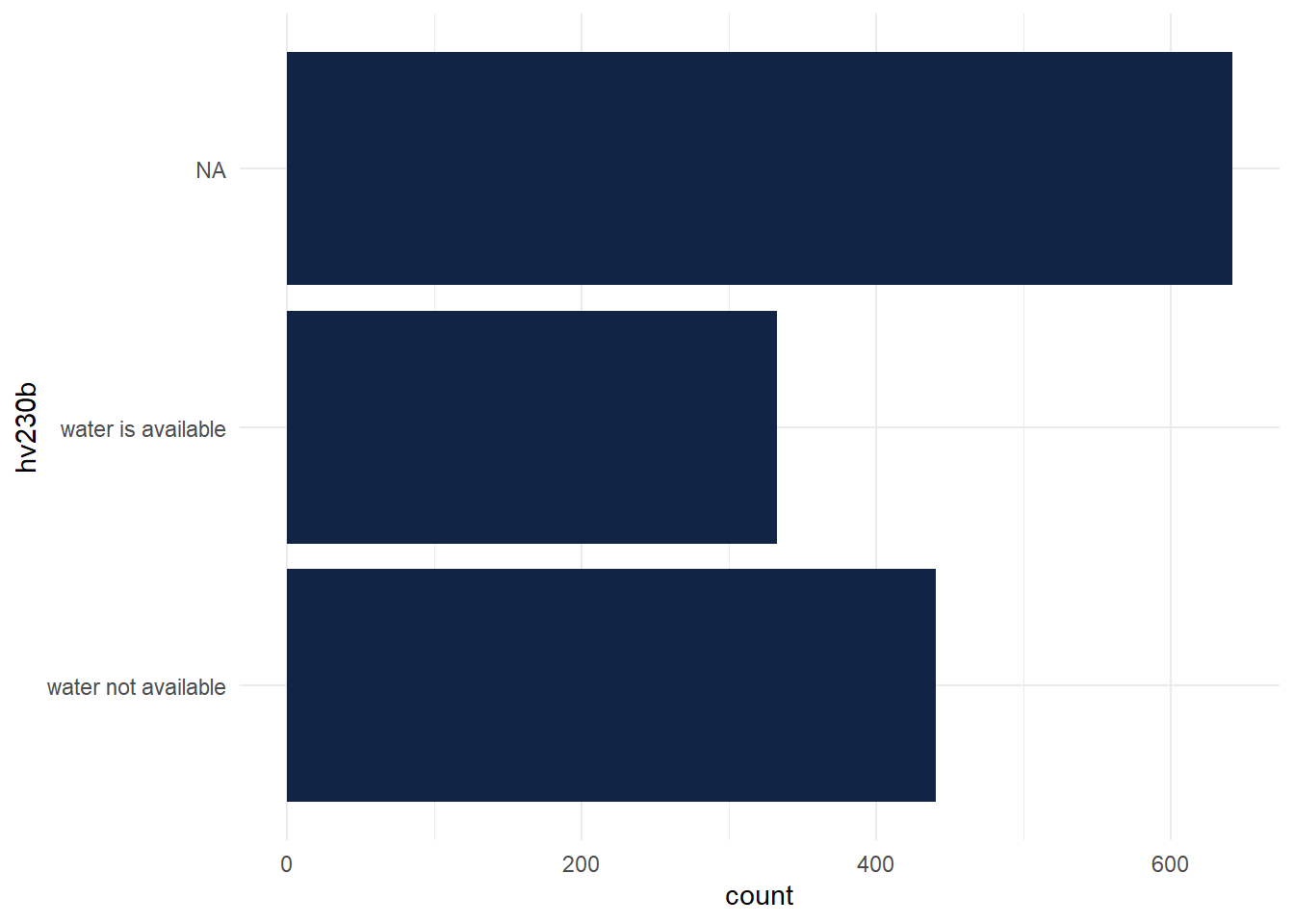
Parmi les répondants à cette question (près de 55% des ménages), seulement près d’un tiers a accès à l’eau pour se laver les mains.
- …Selon l’âge des chefs de ménage
La variable hv220 (age) est de type facteur, on peut calculer la répartition.
freq(Be_Menages$hv220,cum=T) n % val% %cum val%cum
16 2 0.1 0.1 0.1 0.1
17 1 0.1 0.1 0.2 0.2
18 2 0.1 0.1 0.4 0.4
19 5 0.4 0.4 0.7 0.7
20 6 0.4 0.4 1.1 1.1
21 9 0.6 0.6 1.8 1.8
22 17 1.2 1.2 3.0 3.0
23 17 1.2 1.2 4.2 4.2
24 17 1.2 1.2 5.4 5.4
25 41 2.9 2.9 8.3 8.3
26 17 1.2 1.2 9.5 9.5
27 29 2.0 2.0 11.5 11.5
28 49 3.5 3.5 15.0 15.0
29 30 2.1 2.1 17.1 17.1
30 55 3.9 3.9 21.0 21.0
31 29 2.0 2.0 23.0 23.0
32 52 3.7 3.7 26.7 26.7
33 31 2.2 2.2 28.9 28.9
34 30 2.1 2.1 31.0 31.0
35 51 3.6 3.6 34.6 34.6
36 18 1.3 1.3 35.9 35.9
37 43 3.0 3.0 38.9 38.9
38 28 2.0 2.0 40.9 40.9
39 26 1.8 1.8 42.7 42.7
40 53 3.7 3.7 46.5 46.5
41 35 2.5 2.5 48.9 48.9
42 32 2.3 2.3 51.2 51.2
43 28 2.0 2.0 53.2 53.2
44 18 1.3 1.3 54.4 54.4
45 61 4.3 4.3 58.8 58.8
46 21 1.5 1.5 60.2 60.2
47 37 2.6 2.6 62.9 62.9
48 17 1.2 1.2 64.1 64.1
49 24 1.7 1.7 65.7 65.7
50 25 1.8 1.8 67.5 67.5
51 13 0.9 0.9 68.4 68.4
52 27 1.9 1.9 70.3 70.3
53 16 1.1 1.1 71.5 71.5
54 11 0.8 0.8 72.2 72.2
55 30 2.1 2.1 74.4 74.4
56 17 1.2 1.2 75.6 75.6
57 33 2.3 2.3 77.9 77.9
58 17 1.2 1.2 79.1 79.1
59 7 0.5 0.5 79.6 79.6
60 31 2.2 2.2 81.8 81.8
61 17 1.2 1.2 83.0 83.0
62 20 1.4 1.4 84.4 84.4
63 11 0.8 0.8 85.2 85.2
64 3 0.2 0.2 85.4 85.4
65 26 1.8 1.8 87.2 87.2
66 13 0.9 0.9 88.1 88.1
67 15 1.1 1.1 89.2 89.2
68 19 1.3 1.3 90.5 90.5
69 11 0.8 0.8 91.3 91.3
70 26 1.8 1.8 93.1 93.1
71 14 1.0 1.0 94.1 94.1
72 10 0.7 0.7 94.8 94.8
73 7 0.5 0.5 95.3 95.3
74 4 0.3 0.3 95.6 95.6
75 10 0.7 0.7 96.3 96.3
76 5 0.4 0.4 96.7 96.7
77 7 0.5 0.5 97.2 97.2
78 6 0.4 0.4 97.6 97.6
79 2 0.1 0.1 97.7 97.7
80 9 0.6 0.6 98.4 98.4
81 3 0.2 0.2 98.6 98.6
82 3 0.2 0.2 98.8 98.8
83 1 0.1 0.1 98.9 98.9
84 1 0.1 0.1 98.9 98.9
85 6 0.4 0.4 99.4 99.4
86 1 0.1 0.1 99.4 99.4
87 2 0.1 0.1 99.6 99.6
88 1 0.1 0.1 99.6 99.6
90 2 0.1 0.1 99.8 99.8
92 2 0.1 0.1 99.9 99.9
95 1 0.1 0.1 100.0 100.0
97+ 0 0.0 0.0 100.0 100.0
don't know 0 0.0 0.0 100.0 100.0Les modalités de la variable h220 sont ordonnées, le calcul des fréquences cumulées a un sens et on peut dire que la moité des chefs de ménages a moins de 42 ans.
Composition des ménages
Ici on se sert des informations des tables Femmes et Enfants pour calculer leur nombre dans les ménages de notre échantillon … On crée un identifiant ménage (hhid) pour chacune des tables. Et on ajoute ce nouvelle variable dans chacune des tables.
- Nombre de femmes par ménage
On génère un compteur pour calculer le nombre de femmes par ménages (qui ont un identifiant de ménage identique): Nbfem. On ajoute cette nouvelle variable dans la table Femmes. Cette variable est une variable numérique de type integer (int) dans R. On peut alors calculer la répartition du nombre de femmes dans les menages.
# Si variable numérique
summary(Be_Femmes22$Nbfem) Min. 1st Qu. Median Mean 3rd Qu. Max.
1.000 1.000 1.000 1.102 1.000 4.000 # Si variable discrète
table(Be_Femmes22$Nbfem)
1 2 3 4
1445 138 6 4 On dénombre 1445 ménages composés d’une femme, 138 de 2 femmes et 10 ménages de 3 ou 4 femmes dans l’echantillon extrait de l’enquête passée au Bénin.
- Nombre moyen d’enfants vivants dans les ménages
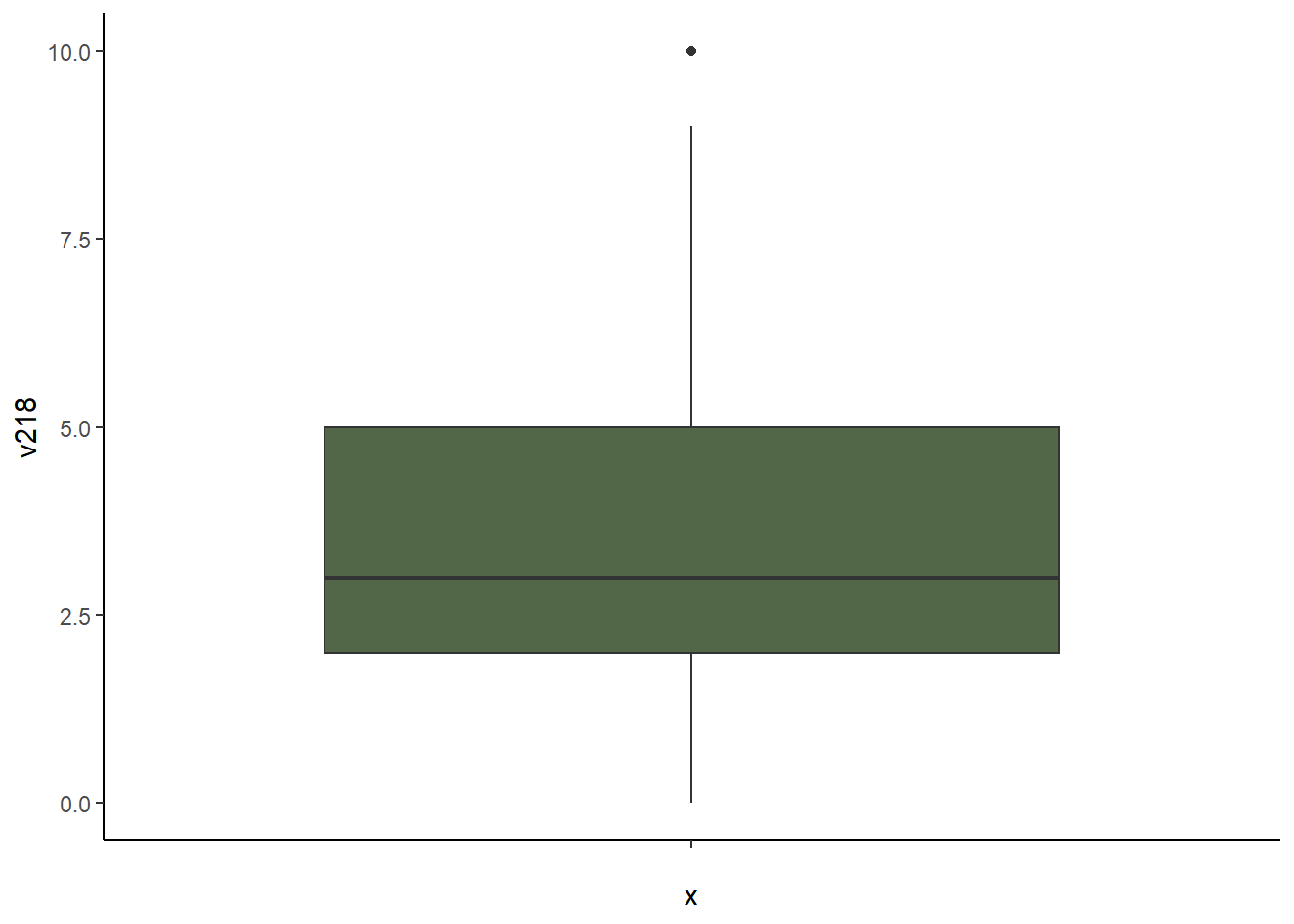
On peut calculer et représenter sur un graphique le nombre d’enfants vivants (v218:Number of living children)
summary(Be_Enfants$v218) Min. 1st Qu. Median Mean 3rd Qu. Max.
0.000 2.000 3.000 3.491 5.000 10.000 Parmi les enfants vivants de la table Enfants on trouve au minimum 0 enfants vivants et 10 au maximum. On trouve en moyenne 3,5 enfants vivants par ménages et la moitié des ménages enquêtés ont 3 enfants.
On peut visualiser ces statistiques sur un graphique de type Box-Plot. Le code ggplot a été récupéré à partir d’un graphique généré avec esquisse lien fiche
ggplot(Be_Enfants) +
aes(x = "", y = v218) +
geom_boxplot(fill = "#526747") +
theme_classic()