L’effet spaghetti en images
Les données utilisées ici sont extraites des bases contextextuelles GGP Datalab de l’Ined.
On va regarder l’évolution du taux de fécondité de 12 pays de 1950 à 2022.
Chergement des données
code year pays y
1 20 1950 France 2.99
2 20 1951 France 2.87
3 20 1952 France 2.81
4 20 1953 France 2.71
5 20 1954 France 2.71
6 20 1955 France 2.71- Les taux de fécondité sont renseignés par la variable y, les années par la variable year et les pays par la variable pays.
En empilant avec ggplot les 12 courbes d’évolution:
graphique avec effet spaghetti
ggplot(df) +
aes(x = year, y = y, colour = pays) +
geom_line(lwd=1) +
scale_color_tableau( palette = "Tableau 20") +
labs(x = "Années", y = "ICF", title = "Indices conjoncturels de fécondité par pays de 1950 à 2022",
caption = "Source: GGP - Datalab Ined", color = "Pays") +
scale_x_continuous(breaks=seq(1950,2020, 10)) +
theme_light() 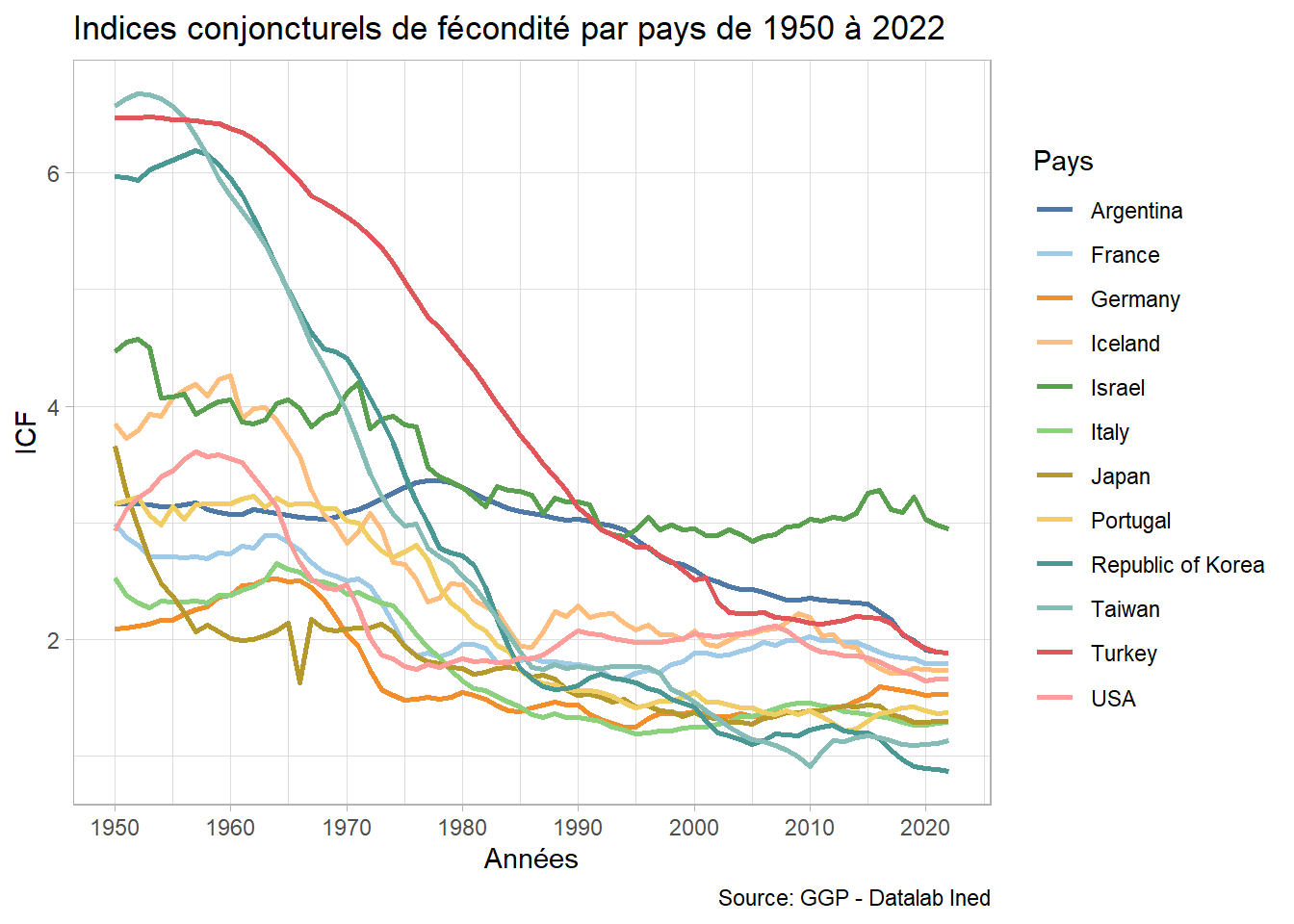
… C’est donc illisible.
- On peut améliorer la lecture et naviguer dans le graphique avec une visualisation dynamique, en utilisant par exemple le package plotly. A réserver à un format de type html.
Graphique interactif avec ggplotly
library(plotly)
p = ggplot(df) +
aes(x = year, y = y, colour = pays) +
geom_line( lwd=1) +
scale_color_tableau( palette = "Tableau 20") +
labs(x = "Années", y = "ICF", title = "Indices conjoncturels de fécondité par pays de 1950 à 2022",
caption = "Source: GGP - Datalab Ined", color = "Pays") +
scale_x_continuous(guide = guide_axis(n.dodge = 2), breaks=seq(1950,2020, 10)) +
scale_y_continuous(breaks=seq(0,6,1)) +
theme_light()
ggplotly(p)- Pour une visualisation statique, il est recommandé de visualiser ce type d’informations à l’aide d’un graphique combiné, appelé small multiples.
Contrôle de l’effet spaghetti avec un graphique combiné
Graphique combiné simple
Par rapport au graphique précédent on va simplement générer des sous graphiques par pays, qui seront combinés avec l’option facet_wrap.
Graphique small multiples
ggplot(df) +
aes(x = year, y = y) +
geom_line(colour = "#C24168", lwd=1.2) +
labs(title = "Taux de fécondité") +
theme_minimal() +
labs(x = "Années",
y = "ICF",
title = "Indices conjoncturels de fécondité par pays de 1950 à 2022",
caption = "Source: GGP - Datalab Ined",) +
scale_x_continuous(guide = guide_axis(n.dodge = 2), breaks=seq(1950,2020, 10)) +
scale_y_continuous(breaks=seq(0,6,1)) +
facet_wrap(vars(pays), ncol = 4L)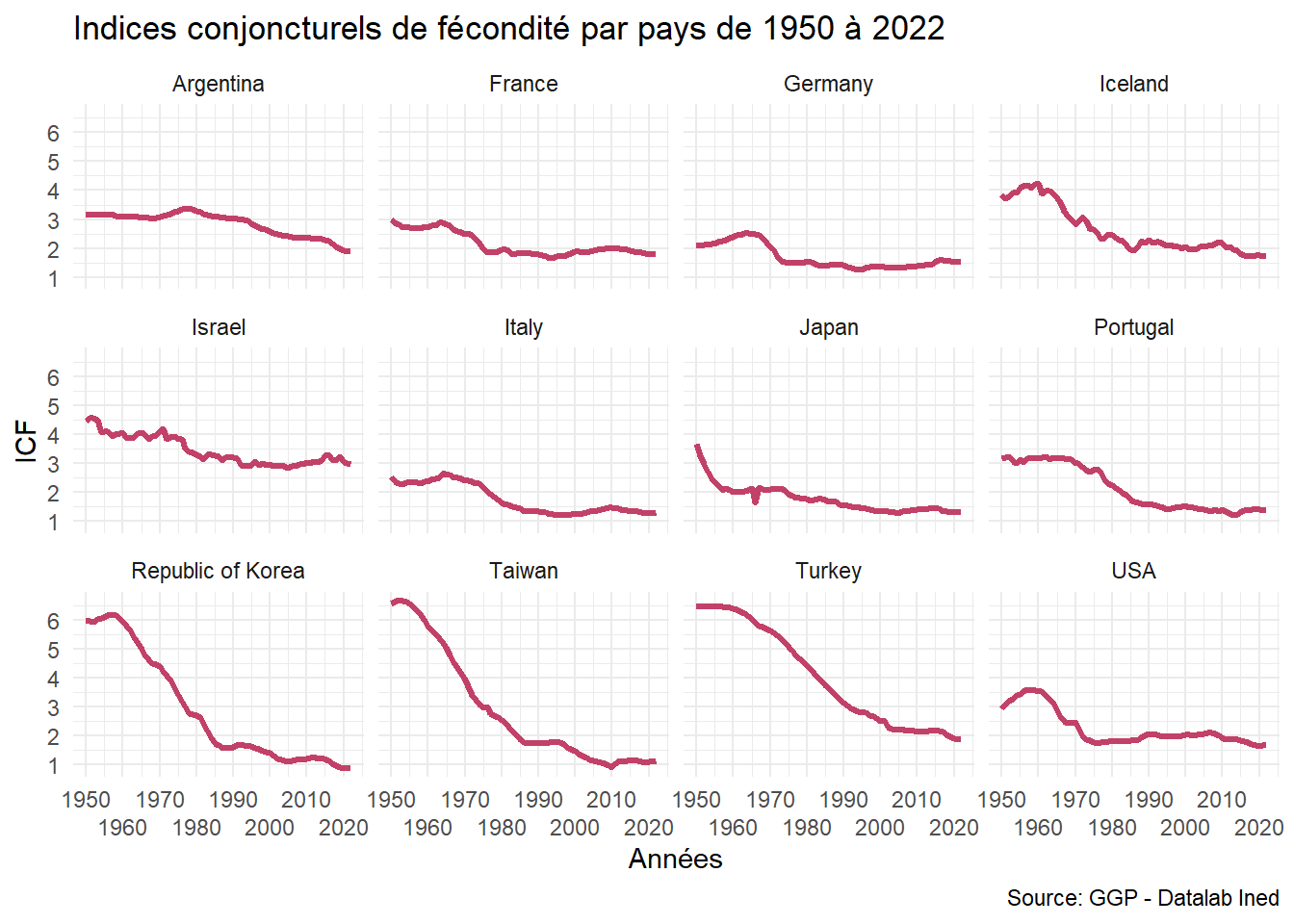
Graphique combiné avec highlighting
On peut combiner les deux approches, en gardant en arrière plan de chaque sous graphique les informations des autres graphiques. On peut donc ici, pour chaque pays, positionner l’information de chaque pays par rapport aux autres (sans distinction).
Le principe du code a été récupéré dans l’excellent support de Yann Holtz Data to viz:
Les courbes en arrière plan ont une épaisseur plus faible (lwd=0.1) et une couleur unique ( color="grey ). Pour faciliter la lecture, le quadrillage a été allégé dans l’option theme().
Graphique small multiples avec highlighting
tmp <- df %>%
mutate(pays2=pays)
ggplot(tmp) +
aes(x = year, y = y) +
geom_line( data=tmp %>% dplyr::select(-pays), aes(group=pays2), color="grey", lwd=0.1) +
geom_line(colour = "#C24168", lwd=1.4) +
labs(title = "Taux de fécondité") +
theme_minimal() +
theme(panel.grid.major.x = element_blank(),
panel.grid.minor.x = element_blank(),
panel.grid.minor.y = element_blank()) +
labs(x = "Années",
y = "ICF",
title = "Indices conjoncturels de fécondité par pays de 1950 à 2022",
caption = "Source: GGP - Datalab Ined",) +
scale_x_continuous(guide = guide_axis(n.dodge = 2), breaks=seq(1950,2020, 10)) +
scale_y_continuous(breaks=seq(0,6,1)) +
facet_wrap(vars(pays), ncol = 4L)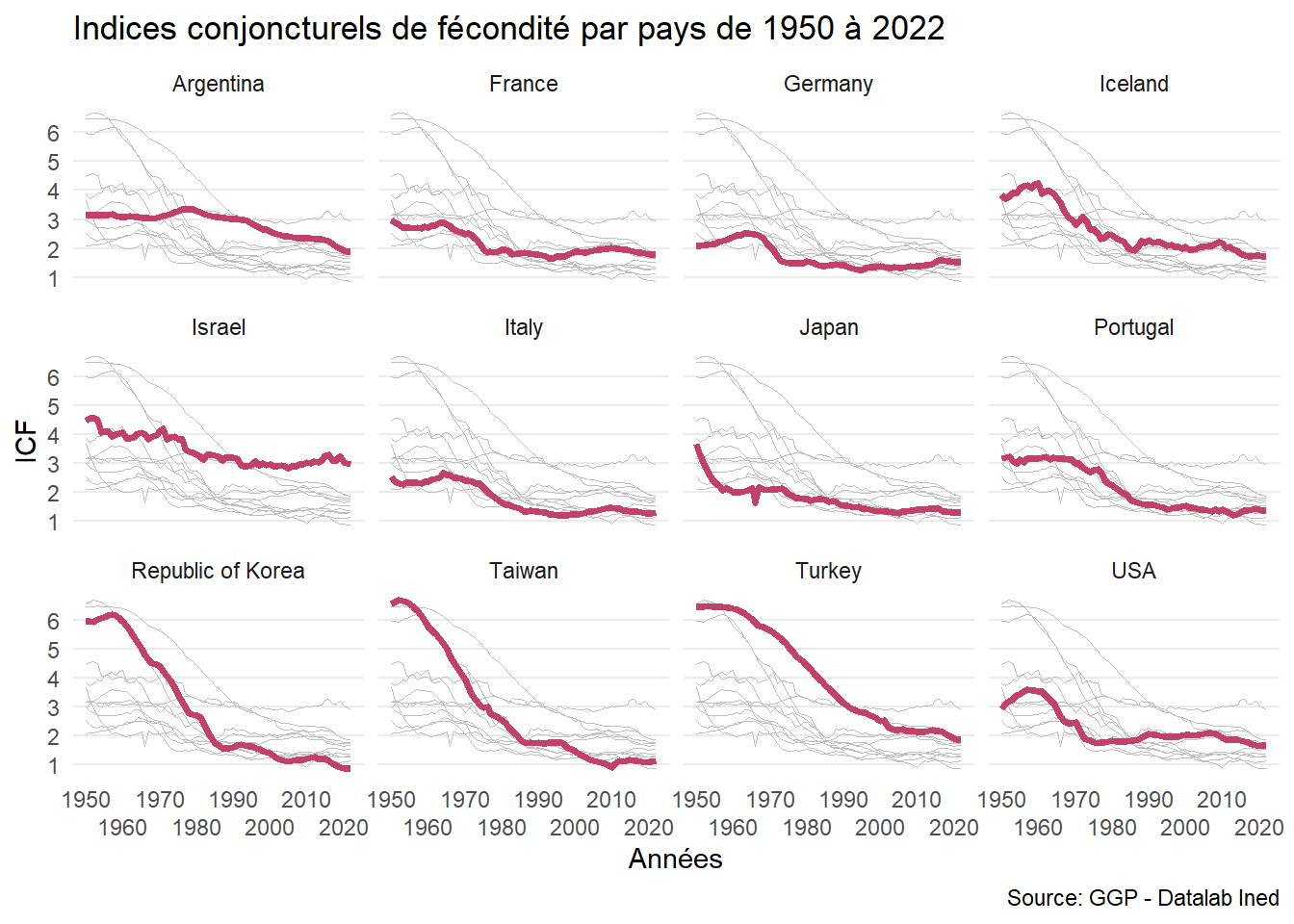
On peut vouloir trier les sous graphiques selon un ordre particulier, ici ils sont simplement affichés par ordre alphabétique.
Si on souhaite par exemple afficher les sous graphiques par ordre décroissant du taux de fécondité en 2022, donc d’Israel en haut à gauche à la Corée du Sud en bas à droite, on réarrange l’ordre de la variable pays avec le code suivant:
Ordre d'affichage des pays
[1] "Israel" "Turkey" "Argentina"
[4] "France" "Iceland" "USA"
[7] "Germany" "Portugal" "Japan"
[10] "Italy" "Taiwan" "Republic of Korea" [1] France Germany Iceland Israel
[5] Italy Japan Portugal Turkey
[9] USA Argentina Taiwan Republic of Korea
12 Levels: Israel Turkey Argentina France Iceland USA Germany ... Republic of KoreaEt on réexécute le graphique précédent:
Graphique avec changement de l'ordre des pays
ggplot(tmp) +
aes(x = year, y = y) +
geom_line( data=tmp %>% dplyr::select(-pays), aes(group=pays2), color="grey", lwd=0.1) +
geom_line(colour = "#C24168", lwd=1.4) +
labs(title = "Taux de fécondité") +
theme_minimal() +
theme(panel.grid.major.x = element_blank(),
panel.grid.minor.x = element_blank(),
panel.grid.minor.y = element_blank()) +
labs(x = "Années",
y = "ICF",
title = "Indices conjoncturels de fécondité par pays de 1950 à 2022",
caption = "Source: GGP - Datalab Ined",) +
scale_x_continuous(guide = guide_axis(n.dodge = 2), breaks=seq(1950,2020, 10)) +
scale_y_continuous(breaks=seq(0,6,1)) +
facet_wrap(vars(pays), ncol = 4L)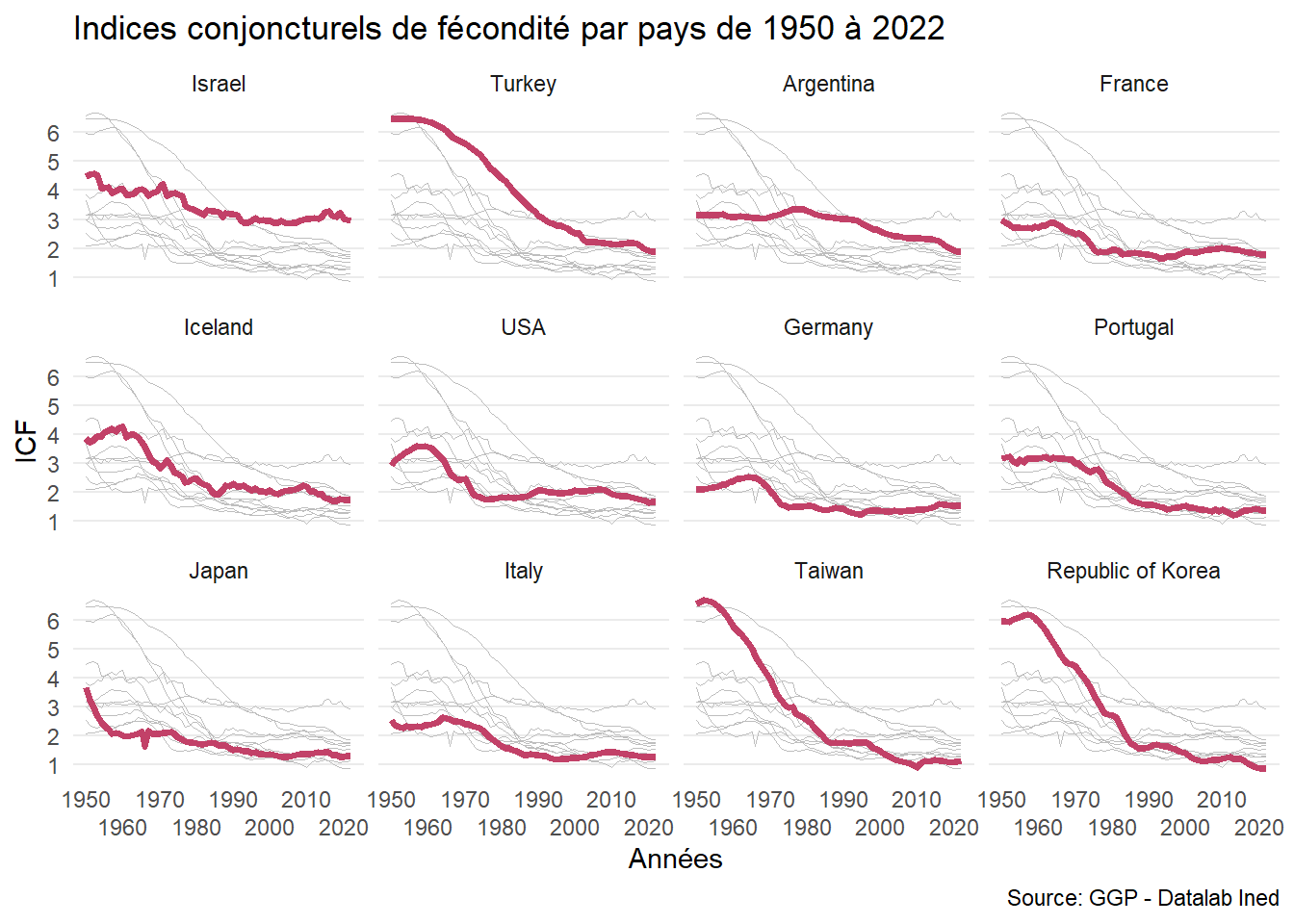
Une fonction pour simplifier et automatiser le code
- Version 0.2 - Mars 2024 [Arno Muller]
- Des options seront ajoutées ultérieurement.
Chargement de la fonction:
Chargement de la fonction
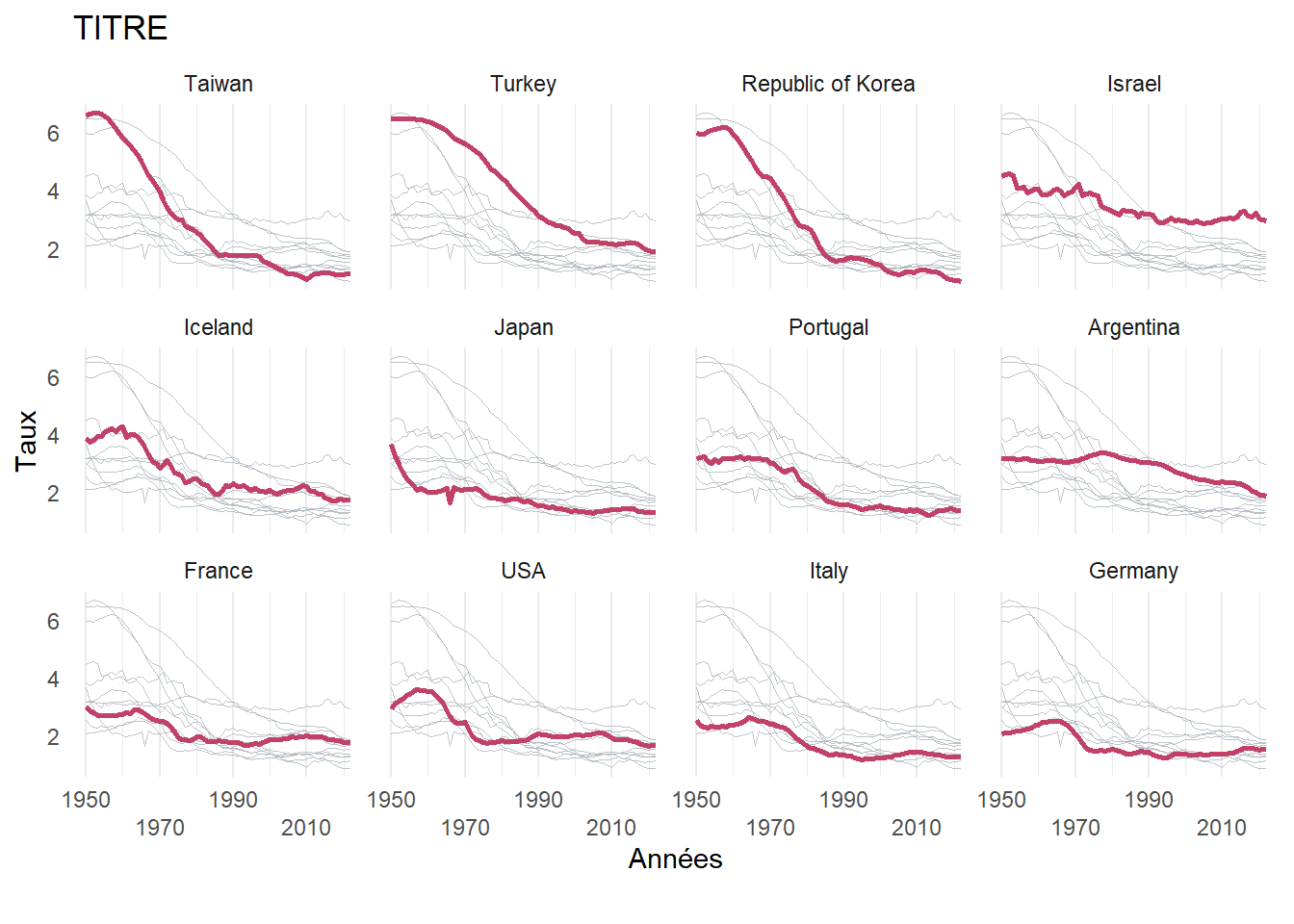
source("https://raw.githubusercontent.com/arnomuller/Fonction_R/main/spag_plot/spag_plot.R")Graphique avec la fonction spag_plot
df <- read.csv("fecondite_ggp.csv")
df = df %>% mutate_if(is.character,as.factor)
spag_plot(df, # Base de données au format long
var_x = "year", # Variable en X (numérique)
var_y = "y", # Variable en Y (numérique)
var_group= "pays", # Variable de groupe (factor)
ordre = 1950, # Ordre des plots ("alpha", valeur num de var_x, un vecteur)
decroiss = "oui", # Ordre décroissant de l'ordre choisi au dessus
titre = "TITRE", # Choix du titre
titre_x = "Années", # Choix du titre de l'axe X
titre_y ="Taux", # Choix du titre de l'axe Y
source = "", # Source des données
interval_x = 20, # Echelle de X
graduation_y = FALSE, # Graduation sur l'axe Y : TRUE/FALSE
n_col = 6, # Nombre de colonnes pour les graphiques
alignement_x = 2, # Nombre d'étiquettes à superposer avant de revenir sur l'axe.
col_line = "#C24168", # Couleur de la ligne principale
lwd_line = 1, # Epaisseur de la ligne principale
transp_line = 1, # Transparence de la ligne principale
type_line = "solid", # Type de ligne : solid, dashed, dotdash, longdash, twodash
col_line_bg = "#e0a0b3", # Couleur lignes secondaires
lwd_line_bg = 0.1, # Epaisseur lignes secondaires
transp_line_bg = 0.8, # Transparence lignes secondaires
type_line_bg = "solid")# Type lignes secondaires 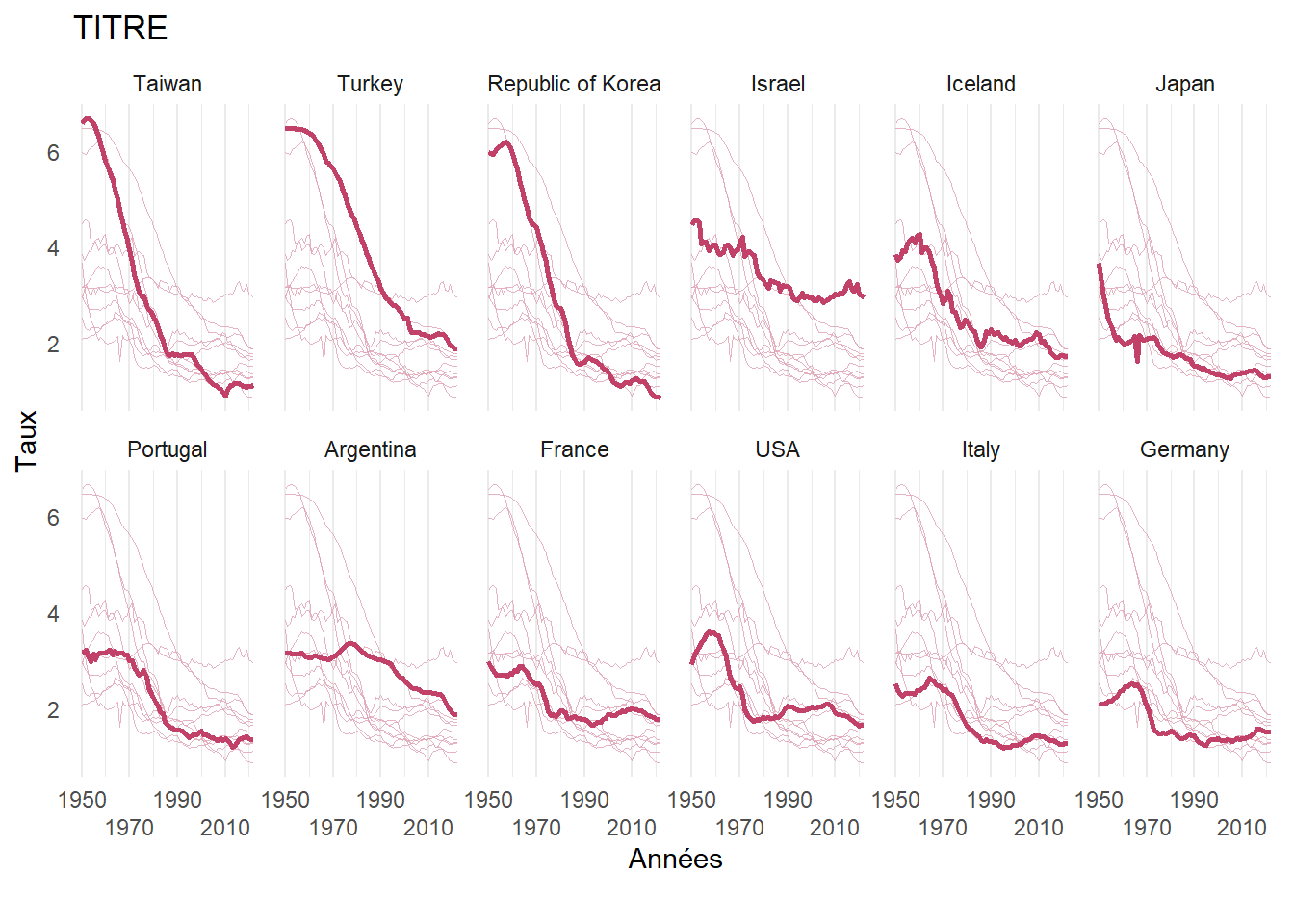
- En changeant le nombre de colonnes:
n_col=4. - En changeant la couleur des courbes en arrière plan:
col_line_bg = "#adb5bd".