+-------------------+
| id v1 v2 v3 |
|-------------------|
1. | D 2 5 10 |
2. | E 12 1 8 |
+-------------------+
file base2.dta saved
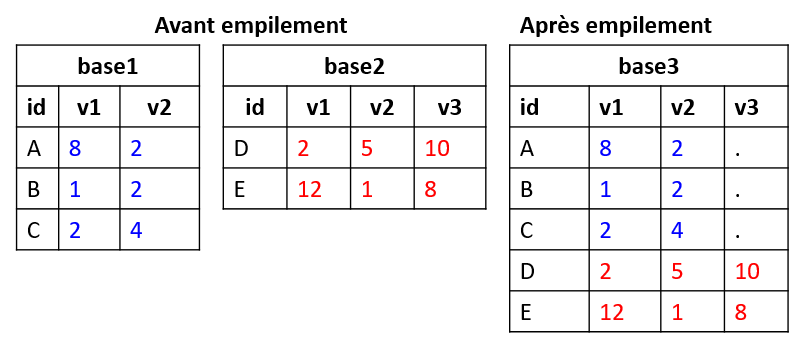
La syntaxe de la commande append consiste à ajouter une ou plusieurs bases à la base active avec l’argument using.
appendusing base1sort idlist
+-------------------+
| id v1 v2 v3 |
|-------------------|
1. | A 8 2 . |
2. | B 1 2 . |
3. | C 2 4 . |
4. | D 2 5 10 |
5. | E 12 1 8 |
+-------------------+
On peut sélectionner les variables de la base qui sera empilée à la base active avec l’option keep.
Dans l’exemple, si la base active est base1, on peut ne pas vouloir ajouter la variable v3 seulement renseignée pour les observations de base2.
use base1, clearappendusing base2, keep(id v1 v2)list
(variable id was str6, now str20 to accommodate using data's values)
+--------------+
| id v1 v2 |
|--------------|
1. | A 8 2 |
2. | B 1 2 |
3. | C 2 4 |
4. | D 2 5 |
5. | E 12 1 |
+--------------+
Si les informations précédentes étaient ventilées dans trois bases, une par variable v, et avec le même niveau d’observation (A,B,C,D,E dans les 3 bases), l’utilisation de append conduirait à une structure empilée non souhaitable avec une réplication des id.
Pour obtenir la base finale proprement appariée, il convient de faire une fusion horizontale contrôlée par une une clé d’identification.
6.1.2 Merge
Stata demande que les bases soient soit triées (sort) sur la clé d’appariement en amont de l’opération. Sinon un message d’erreur sera renvoyé.
La base active (ouverte) est appelée base master
La base qui sera appariée à la base ouverte est appelée base using1
Syntaxe minimale 1 avec préfixes:
merge [1:1] [1:m][m:1] id_variables(s) using nom_base
Ici on peut apparier plus de deux bases.
On dispose d’une sécurité si les niveaux d’identification sont différents.
6.1.2.1 Même niveau d’identification
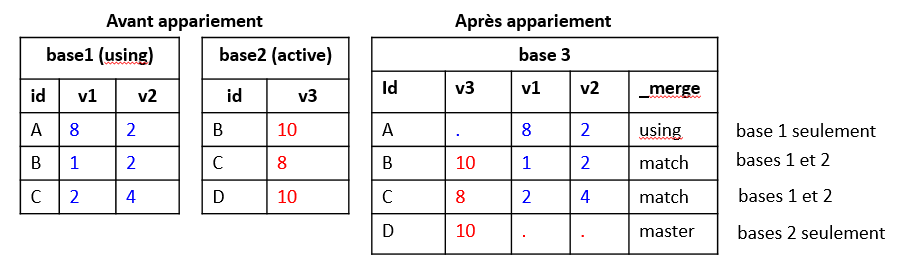
Partons des informations suivantes: - Base1 comprend la variable d’identification id (observations A,B,C) et de deux variables numériques v1 et v3 - Base2 comprend la même variable d’identification id (observations B,C,D) et de la variable numérique v3
Le niveau d’identification est identique dans les deux bases. Il s’agit donc d’un merge 1:1 [One to One]
On va de nouveau générer les bases avec input.
clearinput str1 id v1 v2 "A" 8 2 "B" 1 2"C" 2 4 endlistsort idsave base1, replace
+--------------+
| id v1 v2 |
|--------------|
1. | A 8 2 |
2. | B 1 2 |
3. | C 2 4 |
+--------------+
file base1.dta saved
+---------+
| id v3 |
|---------|
1. | B 10 |
2. | C 8 |
3. | D 10 |
+---------+
file base2.dta saved
merge 1:1 id using base1
Result Number of obs
-----------------------------------------
Not matched 2
from master 1 (_merge==1)
from using 1 (_merge==2)
Matched 2 (_merge==3)
-----------------------------------------
L’output affiche le résultat de l’appariement à l’aide d’un t ltrer si nécessaire les observations selon le résultat de l’apariement. Contrairement à d’autres applications, cette opération n’est pas effectuée en amont avec des fonctions où des options spécifiques. Par exemple avec R: left_join, right_join, inner_join. _merge = 1 : observations qui se trouvent seulement dans la base active (master) _merge = 2 : observations qui se trouvent seulement dans la base using (appariée) _merge = 3 : observations communes aux bases master et using.
Les variables de la base master/active sont positionnées en tête de colonnes.
sort idlist
+-------------------------------------+
| id v3 v1 v2 _merge |
|-------------------------------------|
1. | A . 8 2 Using only (2) |
2. | B 10 1 2 Matched (3) |
3. | C 8 2 4 Matched (3) |
4. | D 10 . . Master only (1) |
+-------------------------------------+
Si on souhaite seulement conserver les observations communes aux deux bases (_merge=3):
Pensez à supprimer la variable *_merge* si plusieurs opérations d’appariement sont effectués. La commande ne prévoit pas d’écraser la variable de la fusion précédente.
Situation avec plus d’une base à apparier
On ne peux pas utiliser la syntaxe avec préfixe (ici merge 1:1).
On va ajouter une nouvelle base qui sera appariée avec les deux premières, qui seront donc les deux bases de type using.
clearinput str1 id str3 v4 "A""Non""B""Oui""C""Oui"endlistsort id
+----------+
| id v4 |
|----------|
1. | A Non |
2. | B Oui |
3. | C Oui |
+----------+
merge id using base1 base2order id v1 v2 v3 v4 _merge1 _merge2 _mergelist
(you are using old merge syntax; see [D] merge for new syntax)
+------------------------------------------------------+
| id v1 v2 v3 v4 _merge1 _merge2 _merge |
|------------------------------------------------------|
1. | A 8 2 . Non 1 0 3 |
2. | B 1 2 10 Oui 1 1 3 |
3. | C 2 4 8 Oui 1 1 3 |
4. | D . . 10 0 1 2 |
+------------------------------------------------------+
On obtient maintenant 3 variables _merge:
*_merge1. Donne le résultat de l’appariement entre la nouvelle base et base1*: 0 si seulement dans une seule des deux bases (D), 1 si dans les deux bases (A,B,C).
*_merge2. Donne le résultat de l’appariement entre la nouvelle base et base2*: 0 si seulement dans une seule des deux bases (A,D), 1 si dans les deux bases (B,C).
*_merge*. Résume rapidement le matching entre les bases: on retrouve au moins une fois les observations (A,B,C) dans l’un des deux appariement (_merge=3), on trouve une observation (D) qui ne se trouve que dans une base using (_D_merge=2).
Si l’on souhaite conserver les observations communes aux trois bases, on peut sommer les valeurs de *_merge1* et *_merge2* et conserver les observations dont la valeurs de cette somme est égale au nombre d’appariements; ou faire une sélection des observations avec un filtre conditionnel, ici:
Permet de gagner 70% de durée d’exécution lorsque la volumétrie dépasse 100000 observations
Gère en amont le tri des bases appariée.
6.1.2.2 Niveaux d’identification différents
Un merge de type 1:1 n’est pas possible. Dans l’exemple qui suit la base period_act liste pour deux personnes le statut d’activité observé pour plusieurs périodes soit des observations multiples pour chaque individus, et la base sexe donne une caractéristique unique pour chaque individu. Selon le statut des bases appariée (master ou using), l’appariement est de type 1:m ou m:1.
Si la base active est à observations multiples sur la clé d’identification: m:1
Si la base active est à observations uniques sur la clé d’identification: 1:m
Le tri de la base est régulièrement modifié après ce type d’appariement. Penser donc à retrier les données proprement, surtout quand il s’agit comme ici d’informations biographiques (sort id périodes)
De nouveau les préfixes sont optionnels, et permettent seulement de contrôler l’appariement. On peut sans soucis fusionner des informations contextuelles avec des informations multiples avec seulement merge. Un avertissement se renvoyé à l’exécution de la commande
use sexe, clearmerge id using period_actsort id périodeslist
(you are using old merge syntax; see [D] merge for new syntax)
variable id does not uniquely identify observations in period_act.dta
+-------------------------------------------+
| id sexe périodes Activité _merge |
|-------------------------------------------|
1. | 1 Homme 1 Emploi 3 |
2. | 1 Homme 2 Emploi 3 |
3. | 1 Homme 3 Chômage 3 |
4. | 2 Femme 1 Chômage 3 |
5. | 2 Femme 2 Chômage 3 |
|-------------------------------------------|
6. | 2 Femme 3 Emploi 3 |
7. | 2 Femme 4 Chômage 3 |
+-------------------------------------------+
6.1.2.3 Appariement avec des frames
L’utilisation des frames présentent plusieurs avantages:
Il n’est pas nécessaire de trier les bases concernées par l’appariement.
On peut sélectionner avec la commande frget la ou les variables qui seront récupérées dans la base master. On apparie donc pas des bases en tant que telles, on récupère de l’information de frames liées.
Mieux encore, on peut réaliser des opérations entre observations individuelles et observations contextuelles sans passer par un appariement. Avec les frames, l’opération d’appariement doit être plutôt compris comme un système de liaison entre bases, le transfert d’informations n’étant qu’une opération optionnelle.
Au niveau des désavantages:
Si on ne travaille pas exclusivement sous frames, les bases devront être transformées en frame (voir exemple)
Absence de variable de type *_merge* qui permet de contrôler le résultat de l’appariement.
les prefixes sont uniquement 1:1 et m:1. Cela signifie dans le second cas que la frame active lors de l’opération de liaison doit toujours être celle dont la clé d’identification est de type multiple (niveau individuel).
Peut-être le plus embêtant est l’absence d’appariement pour les informations correspondant à **_merge=2** (Informations seulement présentes dans la base using). Le dernier exemple illustre ce point.
On reprend l’exemple précédent, en transformant dans un premier temps les deux bases en frames.
frame resetframe create period_actframe period_act: use period_actframe create sexeframe sexe: use sexeframe dir
default 0 x 0
period_act 7 x 3; period_act.dta
sexe 2 x 2; sexe.dta
On doit se positionner sur la frame period_act (type m)
frame change period_act
Pour lier les frames on utilise la commande frlink.
Ici on fait un appariement de type m:1, la clé d’identification est de nouveau id. On lie la frame active à la frame sexe et la variable de liaison (ici un alias de la variable id) est appelée link.
frlink m:1 id, frame(sexe) gen(link)
(all observations in frame period_act matched)
Pour importer la variable sexe dans la frame period_act, on utilise la commande frget, en précisant la ou les variable que l’on souhaite récupérer, ainsi que la variable de liaison (une même frame peut avoir plusieurs liaisons. Voir plus loin).
Liaison des frames en présence d’information incomplète
La liaison de frames peut être problématique en présence d’informations incomplètes. Pour faire simple, la liaison des frames permet de faire des appariements de type **_merge=1** et **_merge=3** (présence dans la master seulement ou présence dans la master et la using) mais ne permet pas de récupérer des informations présentes seulement dans la base using).
Pour illustrer cela on va générer une nouvelle frame, de type individus-périodes, avec une variable additionnelle tvc.
Pour id= 1, on a pas d’information dans la frame period_act pour période=4.
Pour id= 2, on a pas d’information dans la frame tvc pour les périodes 3 et 4.
Création de la nouvelle frame (voir le .do, la compilation pour générer ce support complexifie un peu l’opération):
On voit bien que la valeur de tvc pour id=1 et périodes=4 n’a pas été importée (**_merge=2** dans un appariement classique). En revanche, pour id=2, l’incomplétude de l’information dans la base tvc pour les périodes 3 et 4 est bien visible.
Avec un merge classique (on suppose que period_act n’a pas été appariée à sexe):
use tvc, clearsort id périodessave tvc, replaceuse period_act, clearsort id périodesmerge 1:1 id périodes using tvcsort id périodeslist
file tvc.dta saved
Result Number of obs
-----------------------------------------
Not matched 3
from master 2 (_merge==1)
from using 1 (_merge==2)
Matched 5 (_merge==3)
-----------------------------------------
+--------------------------------------------------+
| id périodes Activité tvc _merge |
|--------------------------------------------------|
1. | 1 1 Emploi 0 Matched (3) |
2. | 1 2 Emploi 0 Matched (3) |
3. | 1 3 Chômage 1 Matched (3) |
4. | 1 4 0 Using only (2) |
5. | 2 1 Chômage 1 Matched (3) |
|--------------------------------------------------|
6. | 2 2 Chômage 0 Matched (3) |
7. | 2 3 Emploi . Master only (1) |
8. | 2 4 Chômage . Master only (1) |
+--------------------------------------------------+
On a bien ici l’ajout de l’information correspondant à _merge=2 (Using only)
Un des intérêts des frames, est de faire des opérations entre informations individuelles et contextuelles sans passer par un appariement en amont. Par l’exemple, nous allons voir comment un appariement peut être évité lorsqu’on travaille sur ce genre d’information.
On va générer 2 bases, une individuelle et une contextuelle. La première contient un identifiant individuel (id), le nom de la zône d’appartenance (zone) et les valeurs observées d’une variable x. La seconde contient le nom des zônes et la valeur moyenne de la variable x dans ces espaces.
frame create indivframe indiv: use indivframe create zoneframe zone: use zone
Après avoir lié les deux frames (m:1), on va calculer directement la différence entre la valeur observée pour chaque individu de la variable x et sa moyenne par zone (xmean). On utilise la fonction frval comme argument de la commande generate.
Cette opération permet d’allonger ou d’élargir une base, généralement sur des variables occurencées. Ces occurences peuvent être des séquences ou points chronologiques (valeur d’une variable sur plusieurs années), ou des individus composant un ménage.
Avec Stata, ces opérations de transpositions sont effectuées avec la commande reshape
De large à long: reshape long
De long à large: reshape wide
A noter que la seconde opération est plus gourmande en durée d’exécution. De nouveau si la volumétrie de la base est élevée, disons plus d’une million d’observations, on peut se reporter sur la commande greshape du package gtools. On peut trouver un benchmark sur des données simulées [liens].
Au niveau de la syntaxe:
Il est nécessaire d’avoir une variable d’identification pour réaliser l’opération: cela peut être un identifiant individuel3 si la variations des observations est relatives à des périodes, ou un identifiant ménage si la source de la variation sont les personnes le composant. Ce peut bien évidemment fonctionner avec des zônes géographiques: régions-départements, régions-communes, départements-communes.
Cette variable d’identification doit être renseignée en option: i(var_id)
On indique dans l’expression principale le racine des variables occurencées: si la base est en format large avec les variables revenu1980, revenu1981,….,revenu1990, la racine sera donc revenu. Les occurences peuvent être des lettres (A,B,D…) ou des mots (un,deux,trois…).
Information sur les occurences: selon le type de transposition on doit indiquer en option la variable qui contiendra ou qui contient les occurences. Cette option est j(nom_variable)
si la base est en format large et qu’on souhaite l’allonger, on indique obligatoirement la variable qui sera créée et qui reportera les valeurs des occurences.
si la base est en format long et qu’on souhaite l’élargir, on indique obligatoirement la variable qui contient les occurences.
Selon la transposition, le nom de commande est suivi de long ou wide
Syntaxe de large à long:
reshape long racines_variables_occurencées, i(var_id) j(var_occurences)
On allonger la base sur les variables x1 à x4. La racine est donc x. Pour le choix de la nouvelle variable qui aura pour chaque id les valeurs 1 à 4, on ne peux pas choisir x, qui sera créée automatiquement. Selon le type d’information contenu dans l’occurence, on peut utiliser un nom indiquant une période, un membre de ménage ou une zône géographique. Ici on ca suposer que les occurences sont de nature temporelle, et on choisira t comme nom à la variable de l’option j().
reshapelong x , i(id) j(t)
(j = 1 2 3 4)
Data Wide -> Long
-----------------------------------------------------------------------------
Number of observations 5 -> 20
Number of variables 5 -> 3
j variable (4 values) -> t
xij variables:
x1 x2 ... x4 -> x
-----------------------------------------------------------------------------
On remarque que Stata donne quelques informations sur le résultats de l’opération: variables créées, nombre d’observations dans le nouveau format
On peut repasser au format de départ (large) avec reshape wide
reshapewide x , i(id) j(t)
(j = 1 2 3 4)
Data Long -> Wide
-----------------------------------------------------------------------------
Number of observations 20 -> 5
Number of variables 3 -> 5
j variable (4 values) t -> (dropped)
xij variables:
x -> x1 x2 ... x4
-----------------------------------------------------------------------------
En revanche si on part d’une base longue avec plusieurs dimensions variables
(j = 1 2)
Data Wide -> Long
-----------------------------------------------------------------------------
Number of observations 5 -> 10
Number of variables 6 -> 5
j variable (2 values) -> t
xij variables:
x1 x2 -> x
y1 y2 -> y
-----------------------------------------------------------------------------
(j = 1 2)variable y not constant within idYour data are currently long. You are performing a reshape wide. You typed something like. reshape wide a b, i(id) j(t) There are variables other than a, b, id, t in your data. They must be constant within id because that is the only way they can fit into wide data without loss of information. The variable or variables listed above are not constant within id. Perhaps the values are in error. Type reshape error for a list of the problem observations. Either that, or the values vary because they should vary, in which case you must either add the variables to the list of xij variables to be reshaped, or drop them.
6.3 Allongement d’une base
Section très courte. Pariculièrement utile lorsqu’on manipule des données biographiques avec des durées, et pour faire la mise en forme nécessaire pour une analyse à durée discrète. La commande expand permet de répliquer les lignes, sur une valeur fixe qu’on indique ou sur des valeurs non constantes renseignés dans une variable.
Dans le premier cas la syntaxe est: expand valeur Dans le second cas la synataxe est: expand nom_variable
Remarque: si la valeur sur laquelle est allongée la base a une valeur négative (par exemple des durées négatives), un message indique leur présence.
6.4 Créer des bases d’indicateurs
Dans ce qui suit il est fortement recommandé d’utiliser les frames (Stata 16 minimum). Pour faire ce type d’opérations deux commandes sont disponibles:
la plus utilisée, collapse permet de créer une base d’indicateurs dédiées aux variables quantitatives: moyenne, médiane et autes quantiles, ….
la moins utilisée, contract, est dédiée aux variables catégorielles (effectifs et effectif cumulés, proportions et proportions cumulées).
Pour les pondérations admises, se reporter à l’aide des commandes4.
Ecrasement de la base d’origine
Attention la base sur laquelle on travaille va être écrasée. Si ce n’est pas souhaité:
Utiliser les commandes preserverestore avant et après l’opération.
Générer une frame avec les variables qui seront transformées en indicateurs. On pourra conserver les deux bases dans la sessions, et les utiliser en parallèle.
6.4.1collapse
Les indicateurs disponibles sont les suivants:
mean means (default) median medians p1 1st percentile p2 2nd percentile ... 3rd-49th percentiles p50 50th percentile (same as median) ... 51st-97th percentiles p98 98th percentile p99 99th percentile sd standard deviations semean standard error of the mean (sd/sqrt(n)) sebinomial standard error of the mean, binomial (sqrt(p(1-p)/n)) sepoisson standard error of the mean, Poisson (sqrt(mean/n)) sum sums rawsum sums, ignoring optionally specified weight except observations with a weight of zero are excluded count number of nonmissing observations percent percentage of nonmissing observations max maximums min minimums iqr interquartile range first first value last last value firstnm first nonmissing value lastnm last nonmissing value
Par défaut c’est la moyenne qui est utilisée.
Les résultats peuvent être stratifiées avec une option by().
Syntaxe avec un seul indicateur
collapse [(statistique autre que moyenne) varlist [, by(varlist)]
Dans les exemples, on utilisera preserverestore pour retrouver la base de départ.
On voit que la variable indicateur prend le nom de la variable. On ne peut donc pas générer une liste d’indicateurs sans renommer les variables.
Syntaxe avec plusieurs indicateurs
Dans l’expression principal, on doit donner un nom différent à chaque variable pour chaque indicateur…ce n’est pas très pratique, Stata aurait pu prévoir un moyen de générer par défaut des nom de variable comme mean_varname, min_varname….
Dans le cas de deux indicateurs (median, min) pour deux variable (price, mpg).
Remarque: pour des variables codées sous forme d’indicatrice, on peut générer des proportions ou des pourcentages facilement, ce qui rend la commande contract caduque avec deux modalités (exemple: variable foreign).
6.4.2contract
Même principe, mais le nombre d’indicateurs est limité (effectifs ou proportion, cumulées ou non). Il n’y a pas d’option by mais on peut directement croiser les dimensions avec plusieurs variables. Je n’ai jamais utilisé cette commande en dehors de la formation, donc je n’en donnerai que deux exemples: